Why Latent Dirichlet Allocation Sucks
As I learn more and more about data science and machine learning, I’ve noticed that a lot of resources out there go something like this:
Check out this thing! It’s great at this task! The important task! The one that was impossible/hard to do before! Look how well it does! So good! So fast!
Take this! It’s our algorithm/code/paper! We used it to do the thing! And now you can do the thing too!
Jokes aside, I do think it’s true that a lot of research and resources focus on what things can do, or what things are good at doing. Whenever I actually implement the hyped-up “thing”, I’m invariably frustrated when it doesn’t perform so well as originally described.
Maybe I’m not smart enough to see this, but after I learn about a new technique or tool or model, it’s not immediately obvious to me when not to use it. I think it would be very helpful to learn what things aren’t good at doing, or why things just plain suck at times. Doing so not only helps you understand the technique/tool/model better, but also sharpens your understanding of your use case and the task at hand: what is it about your application that makes it unsuitable for such a technique?
Which is why I’m writing the first of what will (hopefully) be a series of posts on “Why [Thing] Sucks”. The title is provocative but reductive: a better name might be When and Why [Thing] Might Suck… but that doesn’t have quite the same ring to it! In these articles I’ll be outlining what I tried and why it didn’t work: documenting my failures and doing a quick post-mortem, if you will. My hope is that this will be useful to anyone else trying to do the same thing I’m doing.
So first up: topic modelling. Specifically, latent Dirichlet allocation, or LDA for short (not to be confused with the other LDA, which I wrote a blog post about before).
If you’ve already encountered LDA and have seen plate notation before, this picture will probably refresh your memory:
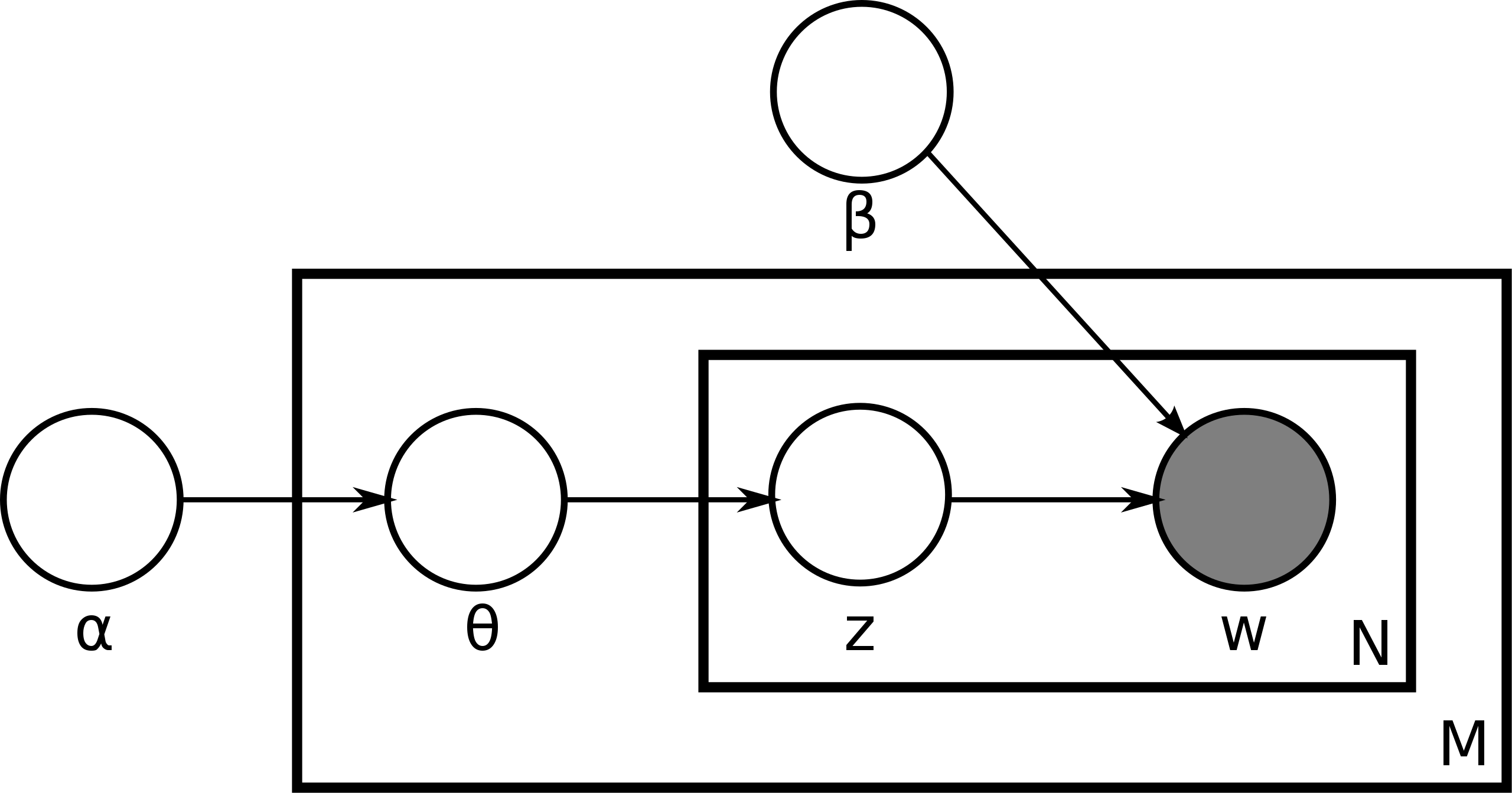
If you don’t know what LDA is, fret not, for there is no shortage of resources about this stuff. I’m going to move on to when and why LDA isn’t the best idea.
tl;dr: LDA and topic modelling doesn’t work well with a) short documents, in which there isn’t much text to model, or b) documents that don’t coherently discuss a single topic.
Wait, what? Did George just say that topic modelling sucks when there’s not much topic, and not much text to model? Isn’t that obvious?
Yes! Exactly! Of course it’s obvious in retrospect! Which is why I was so upset when I realized I spent two whole weeks faffing around with LDA when topic models were the opposite of what I needed, and so frustrated that more people aren’t talking about when not to use/do certain things.
But anyways, <\rant> and let’s move on to why I say what I’m saying.
Recently, I’ve taken up a project in modelling the textual data on Reddit using NLP techniques. There are, of course, many ways one count take this, but something I was interested in was finding similarities between subreddits, clustering comments, and visualizing these clusters somehow: what does Reddit talk about on average? Of course, I turned to topic modelling and dimensionality reduction.
The techniques that I came across first were LDA (latent Dirichlet
allocation) and
t-SNE (t-distributed stochastic neighbor
embedding).
Both techniques are well known and well documented, but I can’t say that using
them together is a popular choice of two techniques. However, there have been
some successes. For instance, ShuaiW had some success with this method when
using it the 20 newsgroups
dataset1;
some work done by Kagglers have yielded reasonable
results,
and the StackExchange community doesn’t think its a ridiculous
idea.
The dataset that I applied this technique to was the Reddit dataset on Google BigQuery, which contains data on all subreddits, posts and comments for as long as Reddit has been around. I limited myself to the top 10 most active subreddits in December 2017 (the most recent month for which we have data, at the time of writing), and chose 20 to be the number of topics to model (any choice is as arbitrary as any other).
I ran LDA and t-SNE exactly as Shuai described on this blog
post1,
except using the great gensim library to
perform LDA, which was built with large corpora and efficient online algorithms
in mind. (Specifically, gensim implements online variational inference with
the EM algorthm, instead of using MCMC-based algorithms, which lda does. It
seems that variational Bayes scales better to very large corpora than collapsed
Gibbs sampling.)
Here are the results:
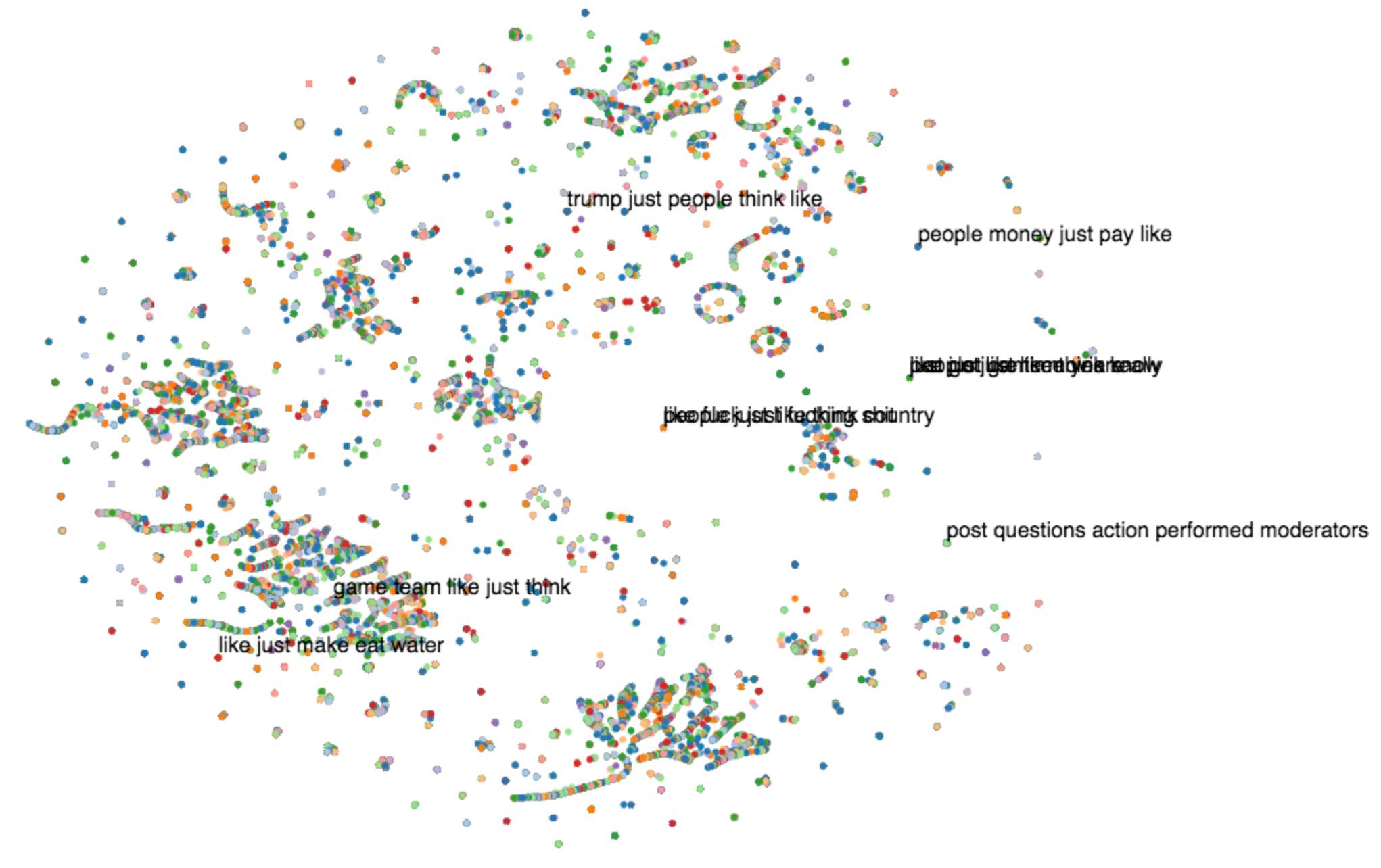
Horrible, right? Nowhere near the well-separated clusters that Shuai got with the 20 newsgroups. In fact, the tiny little huddles of around 5 to 10 comments are probably artifacts of the dimensionality reduction done by t-SNE, so those might even just be noise! You might say that there are at least 3 very large clusters, but even that’s bad news! If they’re clustered together, you would hope that they have the same topics, and that’s definitely not the case here! These large clusters tells us that a lot of comments have roughly the same topic distribution (i.e. they’re close to each other in the high-dimensional topic-space), but their dominant topics (i.e. the topic with greatest probability) don’t end up being the same.
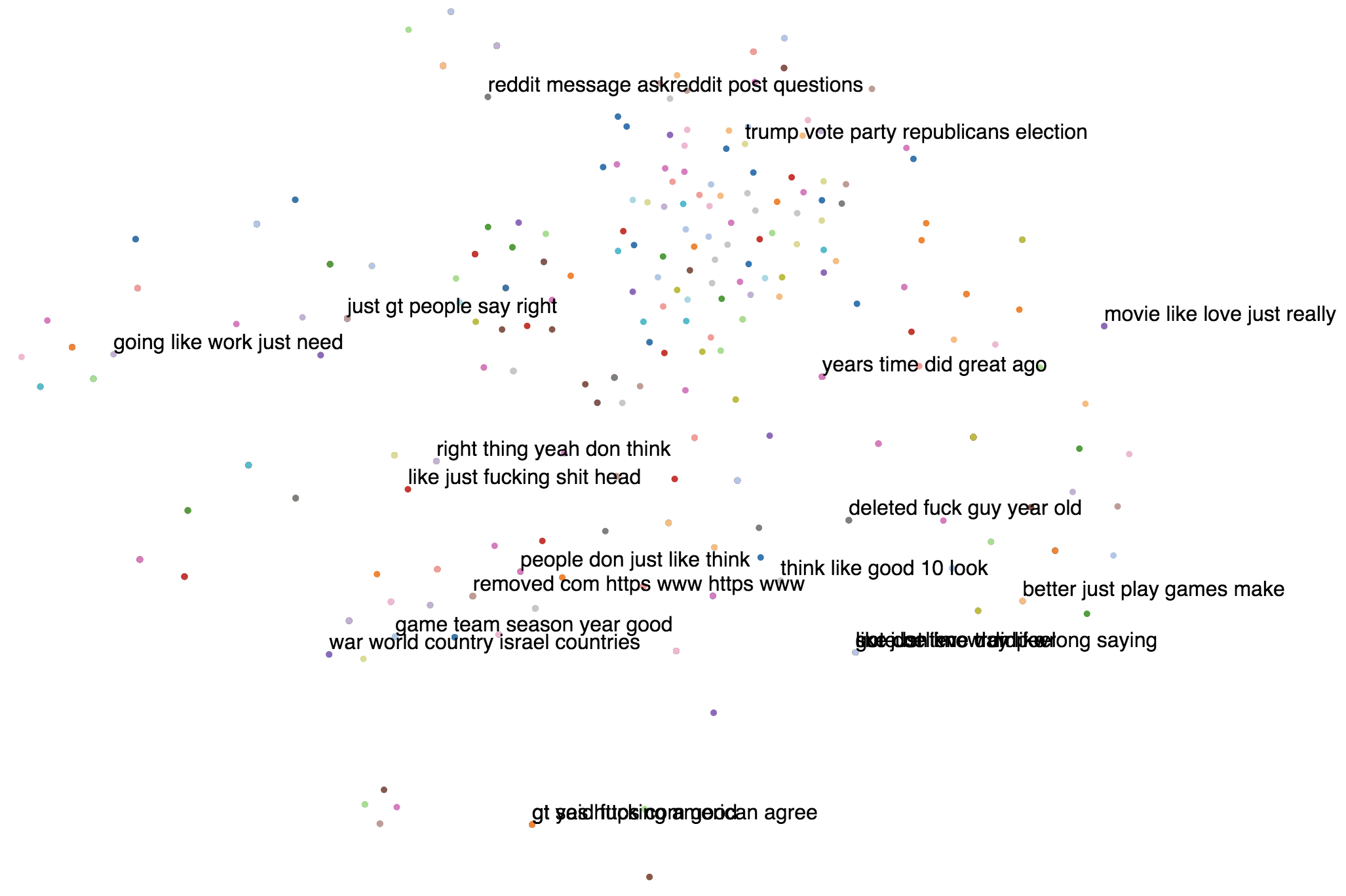
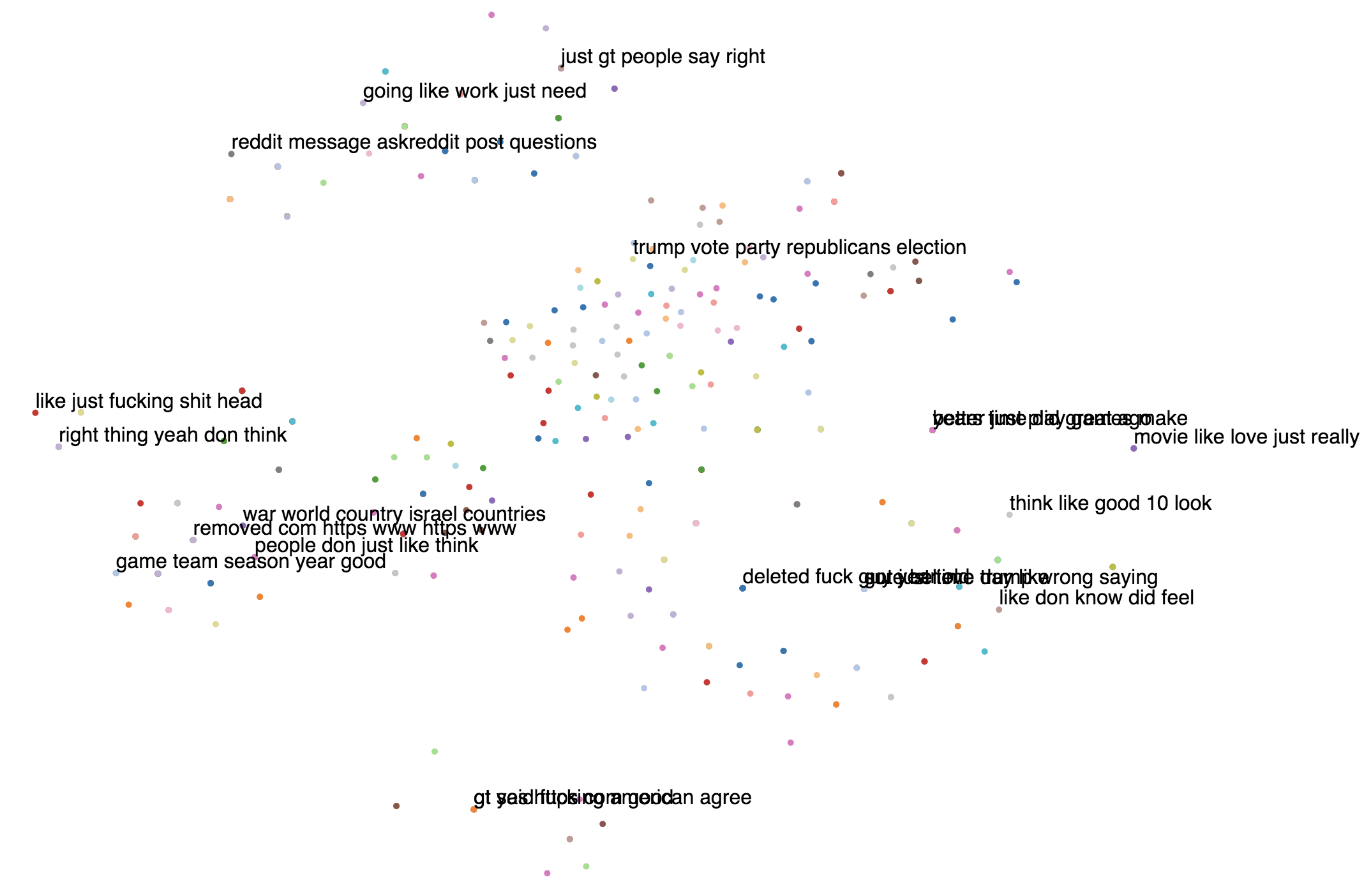
By the way, t-SNE turns out to be a really devious dimensionality reduction
technique, and you really need to
experiment with the perplexity values in order to use it properly. I used the
default perplexity=30 from sklearn for the previous plot, but I repeated the
visualizations for multiple other values and the results aren’t so hot either.
Note that I did these on a random subsample of 1000 comments, so as to reduce
compute time.
So, what went wrong? There’s a nice StackOverflow post that describes the problem well.
Firstly, latent Dirichlet allocation and other probabilistic topic models are very complex and flexible. While this means that they have very high variance and low bias, it also means that they need a lot of data (or data with a decent signal-to-noise ratio) for them to learn anything meaningful. Particularly for LDA, which infers topics on a document-by-document basis, if there aren’t enough words in a document, there simply isn’t enough data to infer a reliable topic distribution for that document.
Secondly, Reddit comments are by their nature very short and very-context dependent, since they respond to a post, or another comment. So not only are Reddit comments just short: it’s actually worse than that! They don’t even discuss a certain topic coherently (by which I mean, they don’t necessarily use words that pertain to what they’re talking about). I’ll give an example:
"I'm basing my knowledge on the fact that I watched the fucking rock fall."
Now, stopwords compose a little less than half of this comment, and they would be stripped before LDA even looks at it. But that aside, what is this comment about? What does the rock falling mean? What knowledge is this user claiming? It’s a very confusing comment, but probably made complete sense in the context of the post it responded to and the comments that came before it. As it is, however, its impossible for me to figure out what topic this comment is about, let alone an algorithm!
Also, just to drive the point home, here are the top 10 words in each of the 20 topics that LDA came up with, on the same dataset as before:
Topic #0:
got just time day like went friend told didn kids
Topic #1:
just gt people say right doesn know law like government
Topic #2:
removed com https www https www tax money http watch news
Topic #3:
people don just like think really good know want things
Topic #4:
years time did great ago ve just work life damn
Topic #5:
movie like love just really school star movies film story
Topic #6:
like just fucking shit head car looks new makes going
Topic #7:
game team season year good win play teams playing best
Topic #8:
right thing yeah don think use internet ok water case
Topic #9:
going like work just need way want money free fuck
Topic #10:
better just play games make ve ll seen lol fun
Topic #11:
like don know did feel shit big man didn guys
Topic #12:
deleted fuck guy year old man amp year old state lmao
Topic #13:
sure believe trump wrong saying comment post mueller evidence gt
Topic #14:
gt yes https com good oh wikipedia org en wiki
Topic #15:
think like good 10 look point lebron just pretty net
Topic #16:
gt said fucking american agree trump thanks obama states did
Topic #17:
trump vote party republicans election moore president republican democrats won
Topic #18:
war world country israel countries china military like happy does
Topic #19:
reddit message askreddit post questions com reddit com subreddit compose message compose
Now, it’s not entirely bad: topic 2 seems like its collecting the tokens from links (I didn’t stopword those out, oops), topic 7 looks like its about football or some other sport, 13 is probably about American politics, and 18 looks like its about world news, etc.
But almost all other topics are just collections of words: it’s not immediately obvious to me what each topic represents.
So yeah, there you have it, LDA really sucks sometimes.
Update (8/12/2018): In retrospect, I think that this whole blog post is summarized well in the following tweet thread. Clustering algorithms will give you clusters because that’s what they do, not because there actually are clusters. In this case, extremely short and context-dependent documents make it hard to justify that there are topic clusters in the first place.
Algorithms that have to report something will always report something, even if it's a bad idea. Please do not use these algorithms unless you have principled reasons why there should be something. https://t.co/kzxZiuBfmm
— \mathfrak{Michael Betancourt} (@betanalpha) August 7, 2018