Multi-Armed Bandits and Conjugate Models — Bayesian Reinforcement Learning (Part 1)
This is the first of a two-part series about Bayesian bandit algorithms. Check out the second post here.
Let’s talk about Bayesianism. It’s developed a reputation (not entirely justified, but not entirely unjustified either) for being too mathematically sophisticated or too computationally intensive to work at scale. For instance, inferring from a Gaussian mixture model is fraught with computational problems (hierarchical funnels, multimodal posteriors, etc.), and may take a seasoned Bayesian anywhere between a day and a month to do well. On the other hand, other blunt hammers of estimation are as easy as a maximum likelihood estimate: something you could easily get a SQL query to do if you wanted to.
In this blog post I hope to show that there is more to Bayesianism than just MCMC sampling and suffering, by demonstrating a Bayesian approach to a classic reinforcement learning problem: the multi-armed bandit.
The problem is this: imagine a gambler at a row of slot machines (each machine being a “one-armed bandit”), who must devise a strategy so as to maximize rewards. This strategy includes which machines to play, how many times to play each machine, in which order to play them, and whether to continue with the current machine or try a different machine.
This problem is a central problem in decision theory and reinforcement learning: the agent (our gambler) starts out in a state of ignorance, but learns through interacting with its environment (playing slots). For more details, Cam Davidson-Pilon has a great introduction to multi-armed bandits in Chapter 6 of his book Bayesian Methods for Hackers, and Tor Lattimore and Csaba Szepesvári cover a breathtaking amount of the underlying theory in their book Bandit Algorithms.
So let’s get started! I assume that you are familiar with:
- some basic probability, at least enough to know some distributions: normal, Bernoulli, binomial…
- some basic Bayesian statistics, at least enough to understand what a conjugate prior (and conjugate model) is, and why one might like them.
- Python generators and the
yieldkeyword, to understand some of the code I’ve written1.
Dive in!
The Algorithm
The algorithm is straightforward. The description below is taken from Cam Davidson-Pilon over at Data Origami2.
For each round,
- Sample a random variable $X_b$ from the prior of bandit $b$, for all $b$.
- Select the bandit with largest sample, i.e. select bandit $B = \text{argmax}(X_b)$.
- Observe the result of pulling bandit $B$, and update your prior on bandit $B$ using the conjugate model update rule.
- Repeat!
What I find remarkable about this is how dumbfoundingly simple it is! No MCMC sampling, no $\hat{R}$s to diagnose, no pesky divergences… all it requires is a conjugate model, and the rest is literally just counting.
NB: This algorithm is technically known as Thompson sampling, and is only one of many algorithms out there. The main difference is that there are other ways to go from our current priors to a decision on which bandit to play next. E.g. instead of simply sampling from our priors, we could use the upper bound of the 90% credible region, or some dynamic quantile of the posterior (as in Bayes UCB). See Data Origami2 for more information.
Stochastic (a.k.a. stationary) bandits
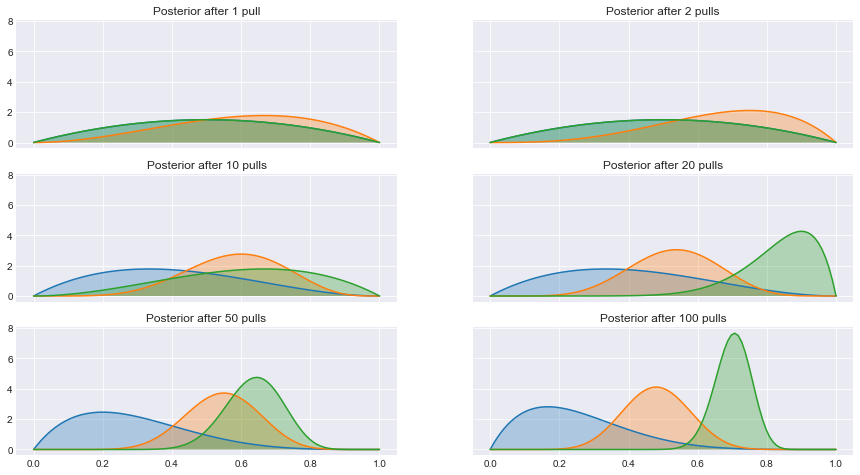
Let’s take this algorithm for a spin! Assume we have rewards which are Bernoulli distributed (this would be the situation we face when e.g. modelling click-through rates). The conjugate prior for the Bernoulli distribution is the Beta distribution (this is a special case of the Beta-Binomial model).
def make_bandits(params):
def pull(arm, size=None):
while True:
# Bernoulli distributed rewards
reward = np.random.binomial(n=1, p=params[arm], size=size)
yield reward
return pull, len(params)
def bayesian_strategy(pull, num_bandits):
num_rewards = np.zeros(num_bandits)
num_trials = np.zeros(num_bandits)
while True:
# Sample from the bandits' priors, and choose largest
choice = np.argmax(
np.random.beta(a=2 + num_rewards, b=2 + num_trials - num_rewards)
)
# Sample the chosen bandit
reward = next(pull(choice))
# Update
num_rewards[choice] += reward
num_trials[choice] += 1
yield choice, reward, num_rewards, num_trials
if __name__ == "__main__":
pull, num_bandits = make_bandits([0.2, 0.5, 0.7])
play = bayesian_strategy(pull, num_bandits)
for _ in range(100):
choice, reward, num_rewards, num_trials = next(play)
Here, pull returns the result of pulling on the arm‘th bandit, and
make_bandits is just a factory function for pull.
The bayesian_strategy function actually implements the algorithm. We only need
to keep track of the number of times we win and the number of times we played
(num_rewards and num_trials, respectively). It samples from all current
np.random.beta priors (where the original prior was a $\text{Beta}(2,
2)$, which is symmetrix about 0.5 and explains the odd-looking a=2+ and
b=2+ there), picks the np.argmax, pulls that specific bandit, and updates
num_rewards and num_trials.
I’ve omitted the data visualization code here, but if you want to see it, check out the Jupyter notebook on my GitHub
Generalizing to conjugate models
In fact, this algorithm isn’t just limited to Bernoulli-distributed rewards: it will work for any conjugate model! Here I implement the Gamma-Poisson model (that is, Poisson distributed rewards, with a Gamma conjugate prior) to illustrate how extensible this framework is. (Who cares about Poisson distributed rewards, you ask? Anyone who worries about returning customers, for one!)
Here’s what we need to change:
- The rewards distribution in the
pullfunction (in practice, you don’t get to pick this, so technically there’s nothing to change if you’re doing this in production!) - The sampling from the prior in
bayesian_strategy - The variables you need to keep track of and the update rule in
bayesian_strategy
Without further ado:
def make_bandits(params):
def pull(arm, size=None):
while True:
# Poisson distributed rewards
reward = np.random.poisson(lam=params[arm], size=size)
yield reward
return pull, len(params)
def bayesian_strategy(pull, num_bandits):
num_rewards = np.ones(num_bandits)
num_trials = np.ones(num_bandits)
while True:
# Sample from the bandits' priors, and choose largest
choice = np.argmax(np.random.gamma(num_rewards, scale=1 / num_trials))
# Sample the chosen bandit
reward = next(pull(choice))
# Update
num_rewards[choice] += reward
num_trials[choice] += 1
yield choice, reward, num_rewards, num_trials
if __name__ == "__main__":
pull, num_bandits = make_bandits([4.0, 4.5, 5.0])
play = bayesian_strategy(pull, num_bandits)
for _ in range(100):
choice, reward, num_rewards, num_trials = next(play)
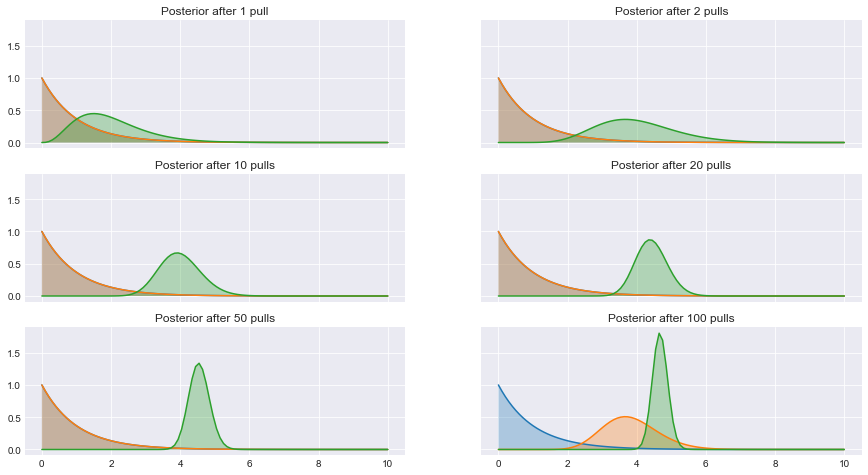
This really demonstrates how lean and mean conjugate models can be, especially considering how much of a pain MCMC or approximate inference methods would be, compared to literal counting. Conjugate models aren’t just textbook examples: they’re (gasp) actually useful!
Generalizing to arbitrary rewards distributions
OK, so if we have a conjugate model, we can use Thompson sampling to solve the multi-armed bandit problem. But what if our rewards distribution doesn’t have a conjugate prior, or what if we don’t even know our rewards distribution?
In general this problem is very difficult to solve. Theoretically, we could place some fairly uninformative prior on our rewards, and after every pull we could run MCMC to get our posterior, but that doesn’t scale, especially for the online algorithms that we have in mind. Luckily a recent paper by Agrawal and Goyal3 gives us some help, if we assume rewards are bounded on the interval $[0, 1]$ (of course, if we have bounded rewards, then we can just normalize them by their maximum value to get rewards between 0 and 1).
This solutions bootstraps the first Beta-Bernoulli model to this new situation. Here’s what happens:
- Sample a random variable $X_b$ from the (Beta) prior of bandit $b$, for all $b$.
- Select the bandit with largest sample, i.e. select bandit $B = \text{argmax}(X_b)$.
- Observe the reward $R$ from bandit $B$.
- Observe the outcome $r$ from a Bernoulli trial with probability of success $R$.
- Update posterior of $B$ with this observation $r$.
- Repeat!
Here I do this for the logit-normal distribution (i.e. a random variable whose
logit is normally distributed). Note that np.expit is the inverse of the logit
function.
def make_bandits(params):
def pull(arm, size=None):
while True:
# Logit-normal distributed returns (or any distribution with finite support)
# `expit` is the inverse of `logit`
reward = expit(np.random.normal(loc=params[arm], scale=1, size=size))
yield reward
return pull, len(params)
def bayesian_strategy(pull, num_bandits):
num_rewards = np.zeros(num_bandits)
num_trials = np.zeros(num_bandits)
while True:
# Sample from the bandits' priors, and choose largest
choice = np.argmax(
np.random.beta(2 + num_rewards, 2 + num_trials - num_rewards)
)
# Sample the chosen bandit
reward = next(pull(choice))
# Sample a Bernoulli with probability of success = reward
# Remember, reward is normalized to be in [0, 1]
outcome = np.random.binomial(n=1, p=reward)
# Update
num_rewards[choice] += outcome
num_trials[choice] += 1
yield choice, reward, num_rewards, num_trials
if __name__ == "__main__":
pull, num_bandits = make_bandits([0.2, 1.8, 2])
play = bayesian_strategy(pull, num_bandits)
for _ in range(100):
choice, reward, num_rewards, num_trials = next(play)
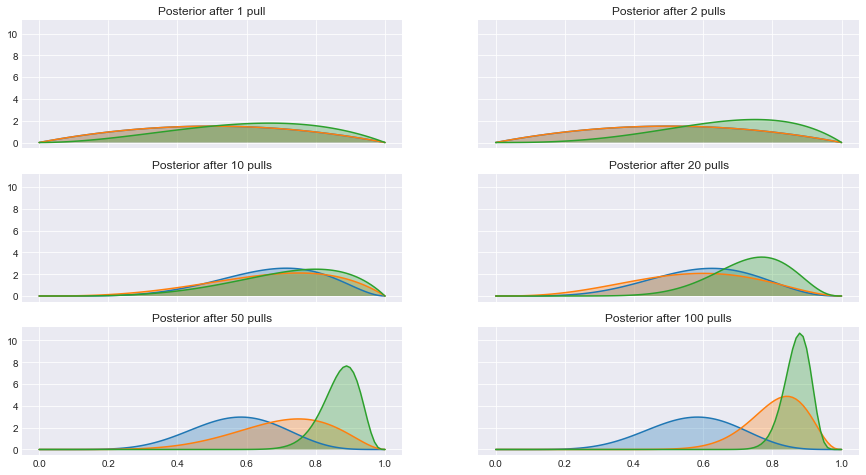
Final Remarks
None of this theory is new: I’m just advertising it! See Cam Davidson-Pilon’s great blog post about Bayesian bandits2 for a much more in-depth treatment, and of course, read around papers on arXiv if you want to go deeper!
Also, if you want to see all the code that went into this blog post, check out the notebook here.
This is the first of a two-part series about Bayesian bandit algorithms. Check out the second post here.
I’ve hopped on board the functional programming bandwagon, and couldn’t help but think that to demonstrate this idea, I didn’t need a framework, a library or even a class. Just two functions! ↩︎
Davidson-Pilon, Cameron. “Multi-Armed Bandits.” DataOrigami, 6 Apr. 2013, dataorigami.net/blogs/napkin-folding/79031811-multi-armed-bandits ↩︎ ↩︎ ↩︎
arXiv:1111.1797 [cs.LG] ↩︎